
8. Visualize Data
Apache Spark has no native module for data visualization. Accordingly, and in order to visualize our data, we need to convert Spark Dataframes to another format. The direct approach we can apply in PySpark is to convert PySpark Dataframes into Pandas Dataframes. To do such conversion in efficient way, we select the set of data features we want to visualize, and retrieve it as Pandas DF. The following function gets Pandas DF using SQL query.
def get_pandasdf_from_sparkdf(spark_df, view_name, query):
'''
This function queries Spark DF, and returns the result table as Pandas DF
INPUTS:
@spark_df: Spark Dataframe to be queried
@view_name: name of SQL view to be created from Spark Dataframe
@query: SQL query to be run on @spark_df
OUTPUTS:
SQL view of @query in Pandas format
'''
spark_df.createOrReplaceTempView(view_name)
return spark.sql(query).toPandas()After getting the Pandas version of data, we can easily visualize it using matplotlib library.
# set SQL query for dataframe df
sqlQuery = """
SELECT cycle, setting1, setting2, setting3,
s1, s2, s3, s4, s5, s6, s7, s8,
s9, s10, s11, s12, s13, s14, s15,
s16,s17, s18, s19, s20, s21
FROM df1
WHERE df1.id=15
"""
# get SQL query result as Pandas DF
plotdata1 = get_pandasdf_from_sparkdf(train_df, "df1", sqlQuery)
The following plot show features’ changes over time for engine # 15 in the training Dataset.
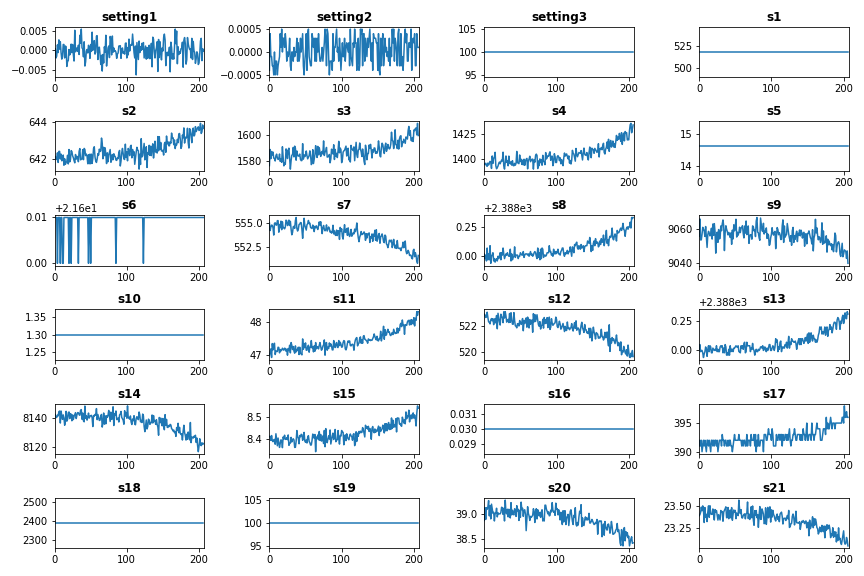
As we note from the above plot, the train data has features with no or very little variance over time. This type of features is almost useless in building predictive data models. Therefore, we will start the next Post of this tutorial by removing low-variance features.
I discovered your internet site from Google and I need to
claim it was a terrific locate. Many thanks!
Thank you!
Do you have any type of pointers for writing articles? That’s where I constantly struggle
and I just wind up looking vacant screen for long time.
We’re a gaggle of volunteers and opening a new scheme
in our community. Your web site offered us with useful information to work on. You
have performed a formidable task and our whole group will probably be
grateful to you.
An impressive share! I’ve just forwarded this onto a coworker
who had been doing a little homework on this. And he in fact bought me breakfast because I discovered it for him…
lol. So allow me to reword this…. Thanks for the meal!!
But yeah, thanx for spending time to discuss this topic here on your site.
I really love your site.. Very nice colors & theme.
Did you build this site yourself? Please
reply back as I’m planning to create my own personal site and would like to know where you got this from or just what the theme is called.
Cheers!
I am using OceanWP Theme