
1. Problem Statement
Medical equipments are expected to act extremely accurate and with (hopefully) no errors, as any uncontrolled failure can threatens patients’ lives. Motivated by this business objective, an Austrian medical equipments manufacturer wants to understand the behavior of his daily-used devices, by studying each device’s electrical consumption, and its influence on that device failure(s). The aim of this case study is to build a machine learning (ML) model that understands the behavior of medical devices, and can predict future failures before they occur. This ML model shall help the manufacturer in building a reliable strategy for maintaining his products. This strategy should avoid – as much as possible – any possible (after-selling) failures, as well as to minimize the number of unnecessary maintenance visits to his clients.
2. Raw Data
2.1 Device Events
Sensor data of medical devices consists of a list of events for each device. Each event has a time stamp and a result. The result of an event can be ok, warning, or failure. If the result is “ok“, this means the device has performed successfully. If an error occurs during the event, the result becomes “failure“. In addition, some events generate “warning” results. These warnings are generated by the engine control system within each device, due to increased power consumption, and does not necessarily leads to a failure.
In addition to events’ results, there is another criteria that classifies each event as either operational or test event. Sensor measurements of test events are taken directly after doing maintenance, when devices performing typically well. All other sensor measurements are labeled as operational events.
2.2 Device Life Cycle
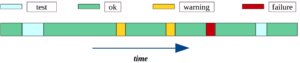
During its life cycle, each device generates one of four possible results after each event (see figure below). If the event runs successfully, “ok” result is generated (green areas). After scheduled maintenance is done, test events are executed directly afterwards. The corresponded sensor measurements of test events reflecting the best possible performance of the device, and referred to as “test” events (pale green areas). From time to time, devices generate “warning” results, due to increased power consumptions (yellow areas). If an event has not been executed properly, the device generates “failure” result (red area).
2.3 Data Consistency
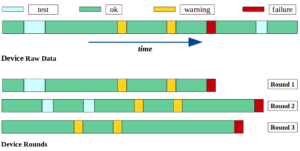
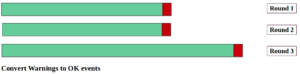
Before modeling the data, we need to obtain the most useful portions of it for our prediction task. Firstly, we group events into discrete rounds. Each round contains events up to a failure. The following diagram explains this step.
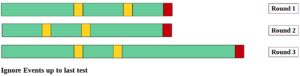
Secondly, and for each round, we ignore events up to the last test result before failure (see the following diagram). The reason is that we do not know the level of deterioration the device reached when it was maintained. Accordingly, this sub-region of device rounds is difficult to be objectively classified.
Finally, and because we don’t have physical relation between warning and failure events, we consider warning events as ok ones. In addition, the target model shall predict failure events, regardless of whether there were warning(s) before them or not.
2.4 Events Distribution
This study was done on three medical devices (A, B, and C), each of which is running under different technical and operational settings. Each device has different number of events per day. Event frequency ranges from 0 to hundreds of events per day. The following figure shows the distribution of events per day for each device in the study.

Because data contains missing values, we use the average frequency of events per day to indicate the daily activity of each device. As the above figure shows, each device has entirely different frequency (device A has nearly 8 events/day, B has 89, and C has 11 events/day).
2.5 Data Labelling
After applying the above steps to raw data, each round is classified into three time regions, based on the deterioration level of the device. These regions are defined as follows:
- Normal Region: This time region typically takes place at beginning of each round. During this period, devices are performing well, and there is no need to schedule them for maintenance.
- Warning Region: This time region stands between Normal and Alarm regions of each round. In this period, the device performance starts to deteriorate, and it’s time to list it in the maintenance schedule.
- Alarm Region: This time region comes directly before failure events. Within this period, the device performance is expected to deteriorate dramatically, and a quick maintenance visit is to be done before it fails.

In this study, and as agreed upon with the manufacturer, we set warning and alarm regions to 7 days each, summing up to two weeks before a failure occurs.
3. Data Preprocessing
3.1 Building Features
Each device has multiple sensors, and during each event, the corresponded measurements of each sensor are recorded. During each event, sensors are consuming different amounts of electrical power. These amounts of electrical power are recorded as a sequence of numbers. The length of measurements sequence for a given event reflects the amount of time the device takes to finish that event. In other words, the longer the sequence is, the longer the device takes to finish the event. Because each device has different number of sensors, and each sensor has different sequence lengths during each event, we calculate the following features out of sensors’ measurements:
- count: length of measurements sequence (also acts as indicator of event duration)
- sum: summation of measurements vector (also acts as indicator of the total amount of power electricity consumed by each sensor during the event)
- avg: mean value of measurements vector.
- var: variance of measurements vector.
- min: minimum value in measurements vector.
- max: maximum value in measurements vector.
- first: first value in measurements vector.
- last: last value in measurements vector.
3.2 Remove Low-Variance Features
After building the above statistics features, we reduce feature space by removing low-variance features from data. In this study, each feature with variance less or equal to 0.5 is removed from data.
3.3 Features Scaling
In order to standardize the range of features, we apply standardization procedure with zero mean and unit variance on the set of features left after removing low-variance ones.
3.4 Dimensionality Reduction
A common preprocessing step before data modeling is to reduce data space. This step helps classifiers to build models quickly (specially for those based on pairwise distance matrices), and makes data visualization much easier. In this study we select Principal Component Analysis (PCA) to reduce our features space. PCA is a widely used technique for dimensionality reduction. It creates a new set of features from the original data, which better describes the variance included within the original features. The following figure shows the amount of variance gained by the first 10 principal components (PCs) of device B (left), along with a scatter plot of data regions, projected by the first two PCs (right).
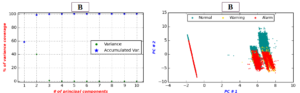
As the figure shows, PCA captures almost 100% of data variance within the first two PCs. The influence can be depicted in the right-side plot, where different regions become more separated. The Normal region appears to be concentrated at the upper half of the plot, while both Warning and Alarm regions are typically located in the lower right area of the graph. In addition, a cluster of Alarm events is separated as a line to the left of the plot, beside small cluster of Normal events.
In Part 2 of this study, we discuss data modeling and evaluation metrics of this predictive maintenance use case.