
8. Visualize Data
Apache Spark has no native module for data visualization. Accordingly, and in order to visualize our data, we need to convert Spark Dataframes to another format. The direct approach we can apply in PySpark is to convert PySpark Dataframes into Pandas Dataframes. To do such conversion in efficient way, we select the set of data features we want to visualize, and retrieve it as Pandas DF. The following function gets Pandas DF using SQL query.
def get_pandasdf_from_sparkdf(spark_df, view_name, query):
'''
This function queries Spark DF, and returns the result table as Pandas DF
INPUTS:
@spark_df: Spark Dataframe to be queried
@view_name: name of SQL view to be created from Spark Dataframe
@query: SQL query to be run on @spark_df
OUTPUTS:
SQL view of @query in Pandas format
'''
spark_df.createOrReplaceTempView(view_name)
return spark.sql(query).toPandas()After getting the Pandas version of data, we can easily visualize it using matplotlib library.
# set SQL query for dataframe df
sqlQuery = """
SELECT cycle, setting1, setting2, setting3,
s1, s2, s3, s4, s5, s6, s7, s8,
s9, s10, s11, s12, s13, s14, s15,
s16,s17, s18, s19, s20, s21
FROM df1
WHERE df1.id=15
"""
# get SQL query result as Pandas DF
plotdata1 = get_pandasdf_from_sparkdf(train_df, "df1", sqlQuery)
The following plot show features’ changes over time for engine # 15 in the training Dataset.
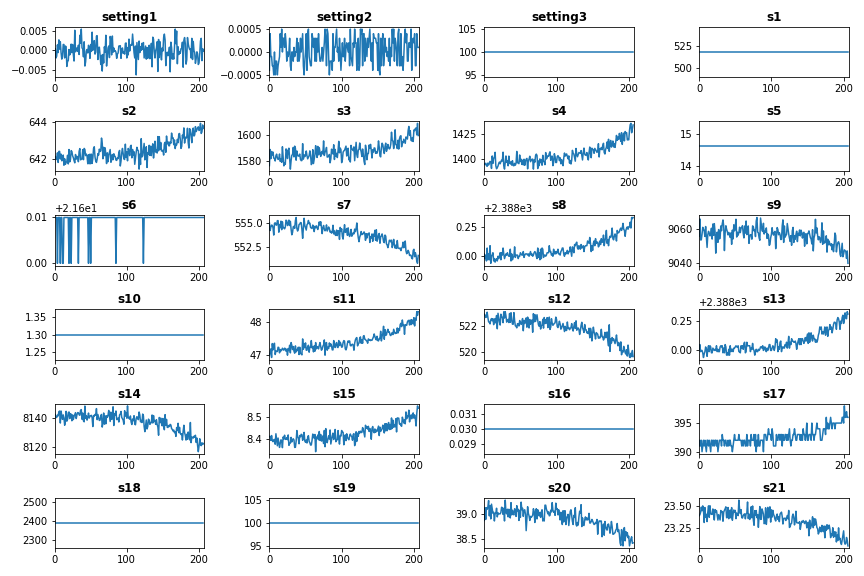
As we note from the above plot, the train data has features with no or very little variance over time. This type of features is almost useless in building predictive data models. Therefore, we will start the next Post of this tutorial by removing low-variance features.