1. Idea
[watch video]
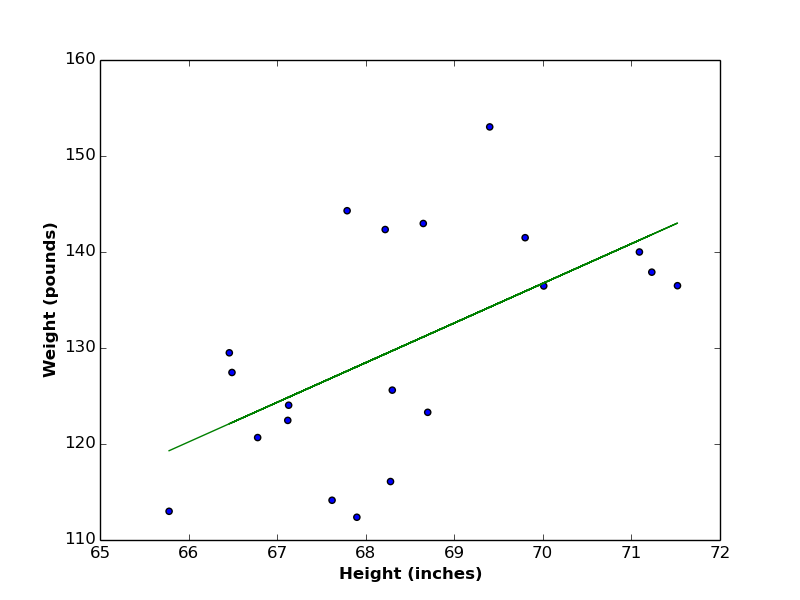
In a previous post, we saw the linear relationship between heights and weights of a group of persons (see the below figure), where both variables are growing together and shrinking together as well.
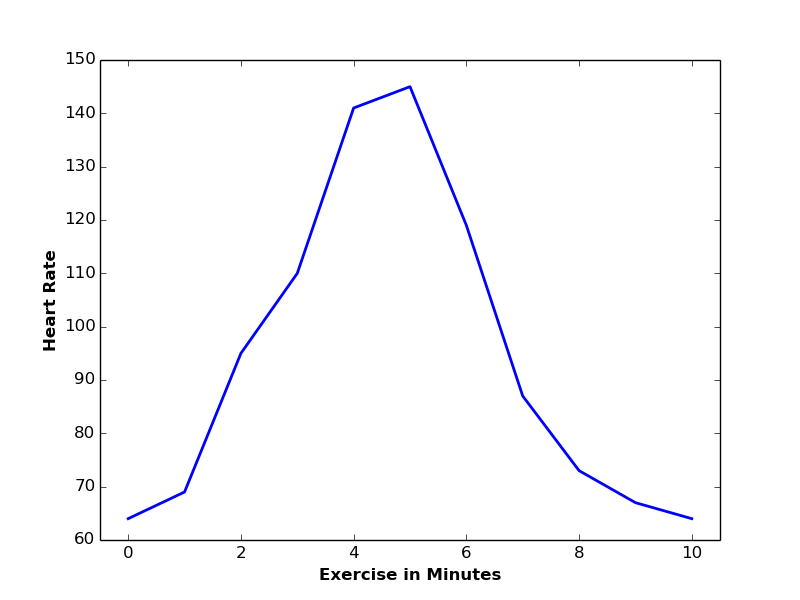
This is however not the case with every two variables. For instance, the average heart beats of a person has a nonlinear relationship with the number of minutes that person is spending in physical exercising. Number of heart beats is rapidly increasing during the first 5 minutes. Afterwards, it starts to decrease.
As another example, levels of testosterone hormone increase in men in the age between 25 and 44 years old (on average). Afterwards, testosterone level starts to decrease monotonically as men become older.
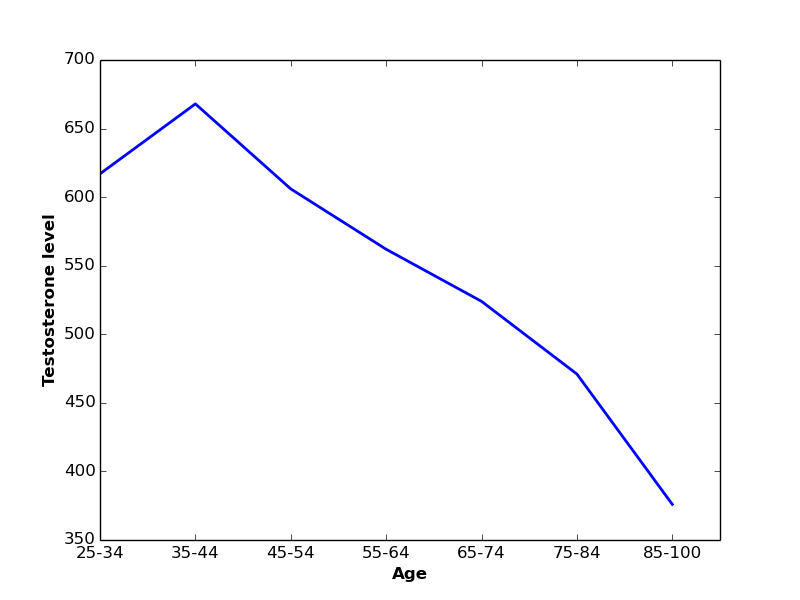
In such scenarios, a linear function can not express the relation between these variables, and a non-linear (polynomial) function should be used instead.
Suppose we have a set of observations represented by two dimensions \(x\) and \(y\), where these observations have non-linear relation, like the below figures.
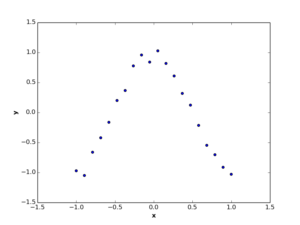
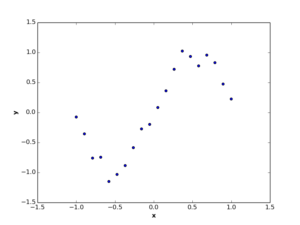
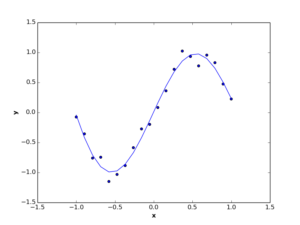
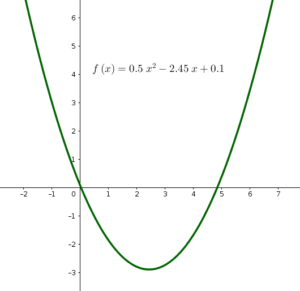
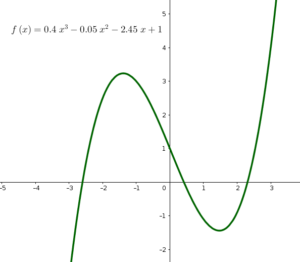
2. Theory
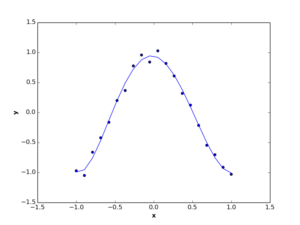
As we explained in linear regression article,we want to find a nonlinear regression function (like the blue function below) that minimize distances (vertical green lines) between true and predicted values of dependent variable \(y\) (i.e Least Squares approach).
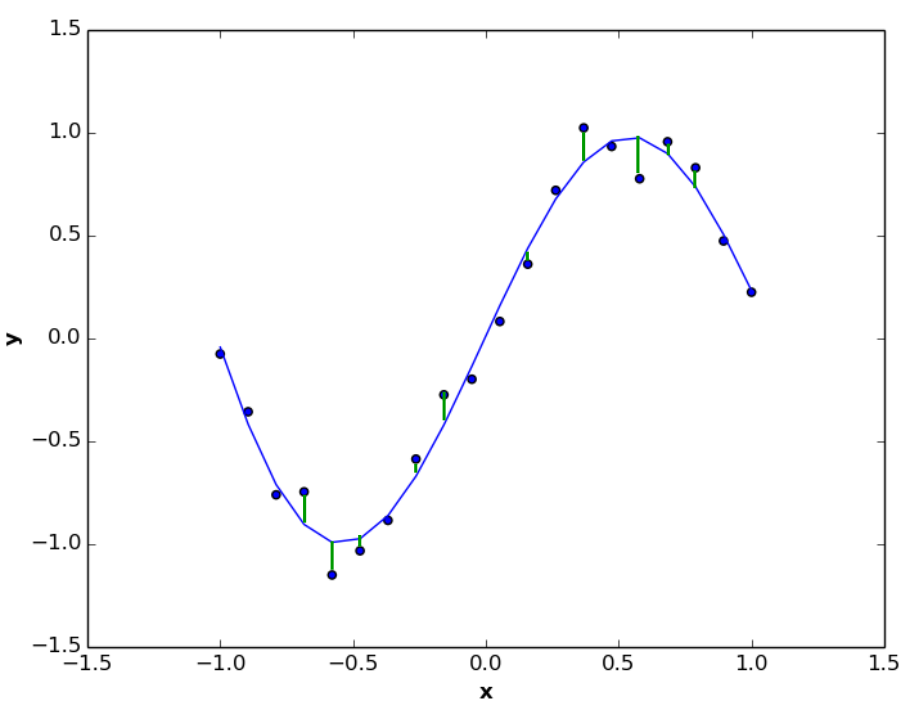
The error function we need to minimize is defined as:
\begin{equation}
E(\mathbf{w}) = \frac{1}{N} \sum\limits_{i=1}^N [y^{(i)}-f(x^{(i)},\mathbf{w})]^2\tag{1}
\end{equation}
which is the same as that of linear regression. The only difference is with hypothesis function \(f(x^{(i)},\mathbf{w})\). This function will be nonlinear with respect to predictor \(x\):
\begin{equation}
f(x^{(i)},\mathbf{w}) = w_0 {x^{(i)}}^0 + w_1 {x^{(i)}}^1 + w_2 {x^{(i)}}^2 + w_3 {x^{(i)}}^3 + … + w_P {x^{(i)}}^P\tag{2}
\end{equation}
Or in a compact form:
\begin{equation}
f(x^{(i)},\mathbf{w}) = \sum\limits_{p=0}^P w_p {x^{(i)}}^p\tag{3}
\end{equation}
where \(P\) is the polynomial degree of function \(f(x^{(i)},\mathbf{w})\).
In order to minimize function \(E(\mathbf{w})\) (Equation 1), we need to put its derivatives with respect to \(\mathbf{w}\) to \(0\):
\begin{equation}
\nabla E(\mathbf{w})= 0\tag{4}
\end{equation}
Let’s compute the derivative of \(E(\mathbf{w})\) with respect to each coefficient \(w \in \mathbf{w}\):
- For \(w_0\):
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_0}= \frac{1}{N} \sum\limits_{i=1}^N \frac{\partial [y^{(i)} – (w_0 + w_1 {x^{(i)}} + w_2 {x^{(i)}}^2 + w_3 {x^{(i)}}^3 + … + w_P {x^{(i)}}^P)]^2}{\partial w_0}\tag{5}
\end{equation}
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_0}= \frac{1}{N} \sum\limits_{i=1}^N \frac{\partial [y^{(i)} – (w_0 + \sum\limits_{p=1}^P w_p {x^{(i)}}^p)]^2}{\partial w_0}\tag{6}
\end{equation}
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_0}= \frac{1}{N} \sum\limits_{i=1}^N \frac{\partial [{y^{(i)}}^2 -2 w_0 y^{(i)} – 2 y^{(i)} \sum\limits_{p=1}^P w_p {x^{(i)}}^p + w_0^2 + 2w_0 \sum\limits_{p=1}^P w_p {x^{(i)}}^p + \sum\limits_{p=1}^P w_p {x^{(i)}}^{2p}]}{\partial w_0}\tag{7}
\end{equation}
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_0}= \frac{1}{N} \sum\limits_{i=1}^N -2 y^{(i)} + 2w_0 + 2 \sum\limits_{p=1}^P w_p {x^{(i)}}^p\tag{8}
\end{equation}
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_0}= \frac{-2}{N} \sum\limits_{i=1}^N [y^{(i)} – (w_0 + \sum\limits_{p=1}^P w_p {x^{(i)}}^p)]\tag{9}
\end{equation}
- For \(w_1\):
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_1}= \frac{-2}{N} \sum\limits_{i=1}^N [y^{(i)} – (w_0 + \sum\limits_{p=1}^P w_p {x^{(i)}}^p)]x^{(i)}\tag{10}
\end{equation}
- For \(w_2\):
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_2}= \frac{-2}{N} \sum\limits_{i=1}^N [y^{(i)} – (w_0 + \sum\limits_{p=1}^P w_p {x^{(i)}}^p)]{x^{(i)}}^2\tag{11}
\end{equation}
- For \(w_p\) of any polynomial degree \(p \in [0:P]\):
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_p}= \frac{-2}{N} \sum\limits_{i=1}^N [y^{(i)} – (w_0 + \sum\limits_{p=1}^P w_p {x^{(i)}}^p)] {x^{(i)}}^p,
\quad \quad
\forall p \in [0:P]\tag{12}
\end{equation}
6. Polynomial Degree Selection (Bias -Variance Tradeoff)
[watch video]
A question may rise in the discussion of nonlinear regression: which polynomial degree (\(p\)) should we use to build our regression function? There is no standard answer to this question. A good way to estimate the value of \(p\) is to try out different values and select between. Your selection should be in the middle between underfitting and overfitting situations.
On the one hand, the case of underfitting (e.g. \(p=1\)) generate a regression function which is highly biased toward erroneous assumptions of training data (like the case of below figure, where nonlinear variable is predicted by linear function), and thus is far from simulating the relationship between target and predictor variables.
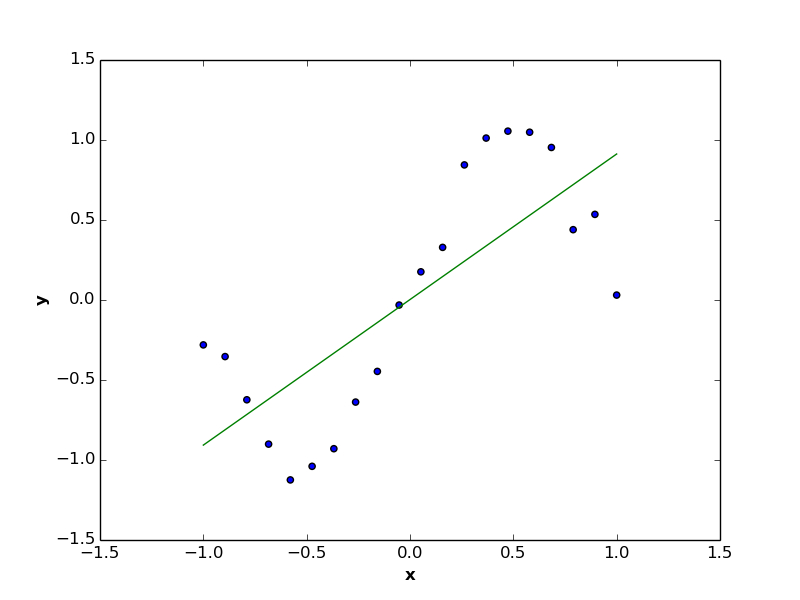
On the other hand, the case of overfitting (e.g. \(p=N-1\) in below figure) generates regression function with high variance, makes it highly sensitive to small fluctuations in the training data, and accordingly recording error rate close to \(0\). Overfitting is usually generating models that can not precisely interact with unseen data, as these models are highly biased to the training set of observations, and the corresponded regression functions are usually quite complicated.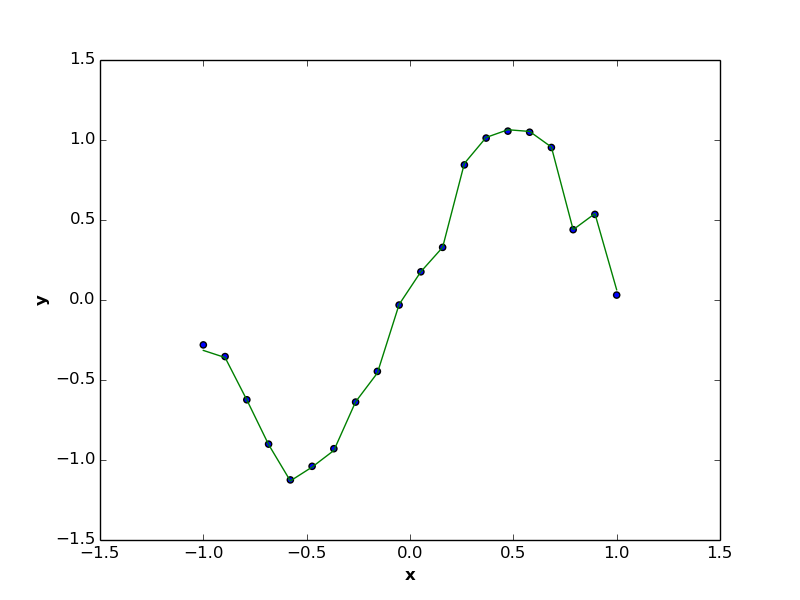
The proper regression model (like the one in the following figure) is usually estimated by making a tradeoff between underfitting and overfitting scenarios, where the regression function is minimizing the error rate, while keeping itself as simple as possible (i.e. with lowest possible number of coefficients).
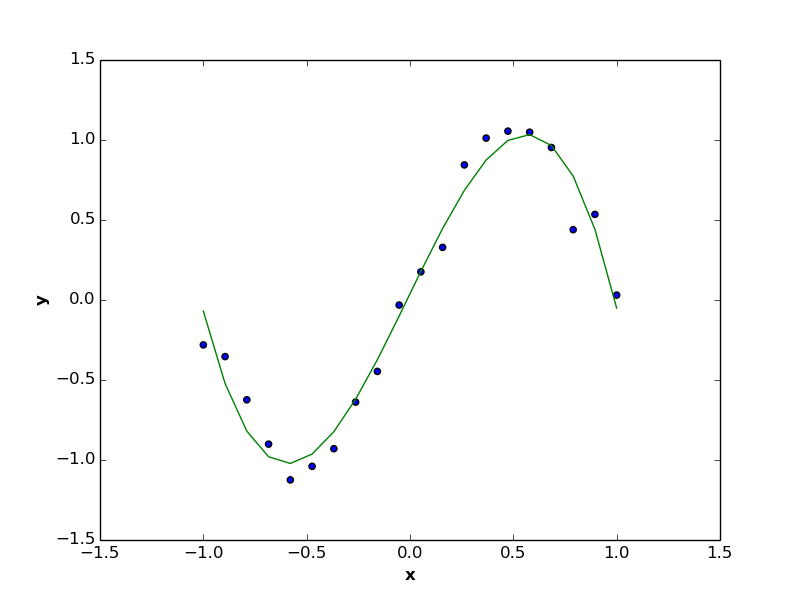
6.1 Regularization
A common technique to overcome the problem of overfitting is to add a penalty term to the error function \(E(\mathbf{w})\). The role of this penalty term – sometimes called also smooth term – is to minimize the number of coefficients used in regression function. Now, we define the new error function (\(\tilde{E}\)) to be:
\begin{equation}
\tilde{E}(\mathbf{w}) = \frac{1}{N} \sum\limits_{i=1}^N [y^{(i)}-f(x^{(i)},\mathbf{w})]^2 + \frac{1}{2} \lambda \sum\limits_{p=1}^P w_p^2\tag{28}
\end{equation}
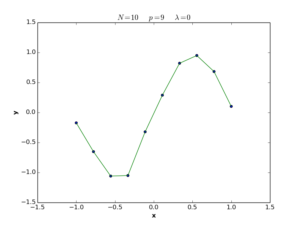
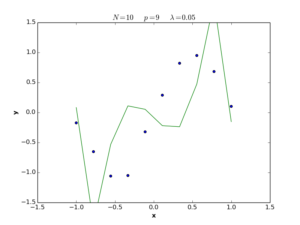
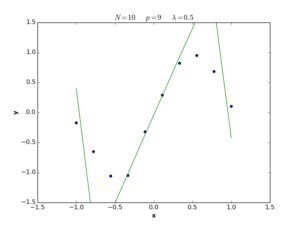
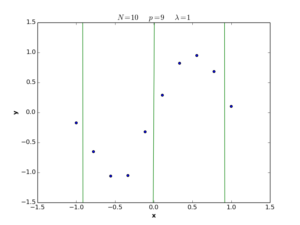
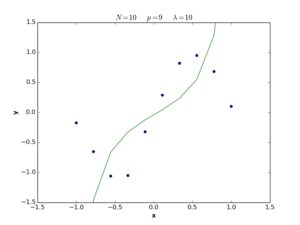
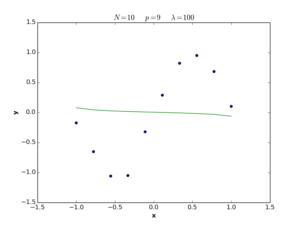
The \(\lambda\) term in equation (28) is called the regularization coefficient, and its role is to control the simplicity of the error function in terms of \(\mathbf{w}\) length. If \(\lambda\) is large, the function tends to be simple, and we move to the underfitting situation, while if \(\lambda\) is small, the function tends to be complex and we move to the overfitting situation. If \(\lambda = 0\), the regularization term is deleted and we return to the definition (1) of error function. The following plots show nonlinear regression functions generated by equation (28) with different \(\lambda\) values.