
1. Remove Low Variance Features
At the end of the previous Post, we saw that some data features has no or very low variance over time. As this class of features is useless in building predictive data models, we want to remove those features to reduce data dimensionality. The following function receives Spark Dataframe as an input, along with the maximum unaccepted variance threshold. The function computes each feature variance, and delete the feature if it’s variance is less or equal to the given threshold.
def spark_remove_low_var_features(spark_df, features, threshold, remove):
'''
This function removes low-variance features from features columns in Spark DF
INPUTS:
@spark_df: Spark Dataframe
@features: list of data features in spark_df to be tested for low-variance removal
@threshold: lowest accepted variance value of each feature
@remove: boolean variable determine if the low-variance variable should be removed or not
OUTPUTS:
@spark_df: updated Spark Dataframe
@low_var_features: list of low variance features
@low_var_values: list of low variance values
'''
# set list of low variance features
low_var_features = []
# set corresponded list of low-var values
low_var_values = []
# loop over data features
for f in features:
# compute standard deviation of column 'f'
std = float(spark_df.describe(f).filter("summary = 'stddev'").select(f).collect()[0].asDict()[f])
# compute variance
var = std*std
# check if column 'f' variance is less of equal to threshold
if var <= threshold:
# append low-var feature name and value to the corresponded lists
low_var_features.append(f)
low_var_values.append(var)
print(f + ': var: ' + str(var))
# drop column 'f' if @remove is True
if remove:
spark_df = spark_df.drop(f)
# return Spark Dataframe, low variance features, and low variance values
return spark_df, low_var_features, low_var_values
# remove low-variance features from data
train_df, train_low_var_features, train_low_var_values = spark_remove_low_var_features(train_df, data_features, 0.05, False)
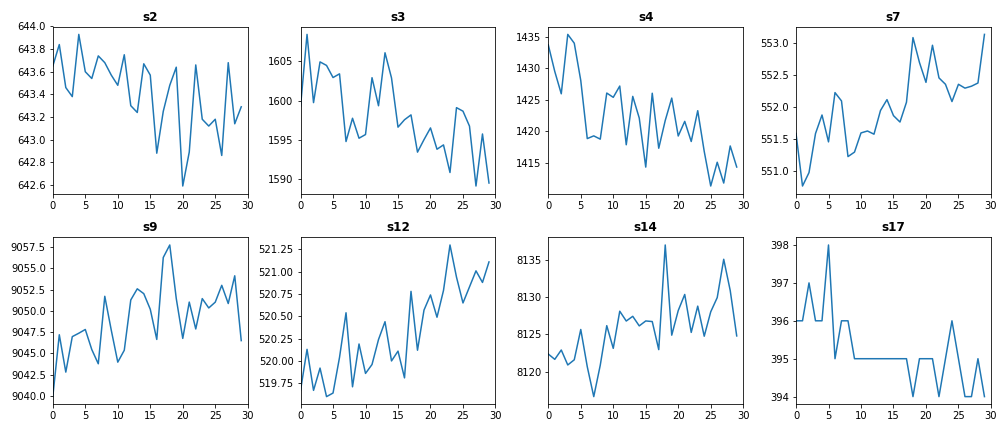
After removing low variance features, we left with eight features in both train and test datasets. The following plot shows train data features of Engine #15 after removing low variance dimensions.
2. Remove Noise
The second data preprocessing step is to remove irregular data readings that may arise over time. To achieve this goal, we apply Moving Average procedure to our data. The following function partition Spark Dataframe by Engines using Window module, and calculate the corresponded rolling average feature of each numerical data feature in that Dataframe.
from pyspark.sql.window import Window
import pyspark.sql.functions as F
def add_rolling_avg_features(df, features, lags, idx, time):
'''
This function adds rolling average features for each asset in DF. The new features
take names OLD_FEATURE+'_rollingmean_'
INPUTS:
@df: Spark Dataframe
@features: list of data features in @df
@lags: list of windows sizes of rolling average method
@idx: column name of asset ID
@time: column name of operational time
OUTPUTS:
@df: Updated Spark Dataframe
'''
# loop over window sizes
for lag_n in lags:
# create Spark window
w = Window.partitionBy(idx).orderBy(time).rowsBetween(1-lag_n, 0)
# loop over data features
for f in features:
# add new column of rolling average of feature 'f'
df = df.withColumn(f + '_rollingmean_'+str(lag_n), F.avg(F.col(f)).over(w))
# return DF
return df
# set lag window to 4 cycles
lags = [4]
# add rolling average features
train_df = add_rolling_avg_features(train_df, data_features, lags, "id", "cycle")
After removing noise from sensor data, we get more smoothing trends over time. The following figure shows the difference before and after removing noise in test dataset.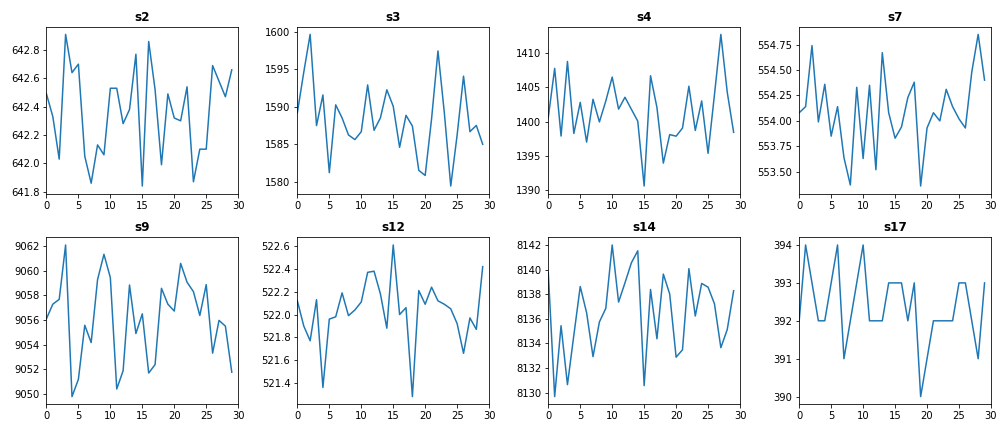
Test Data Before Removing Noise (Engine #15)
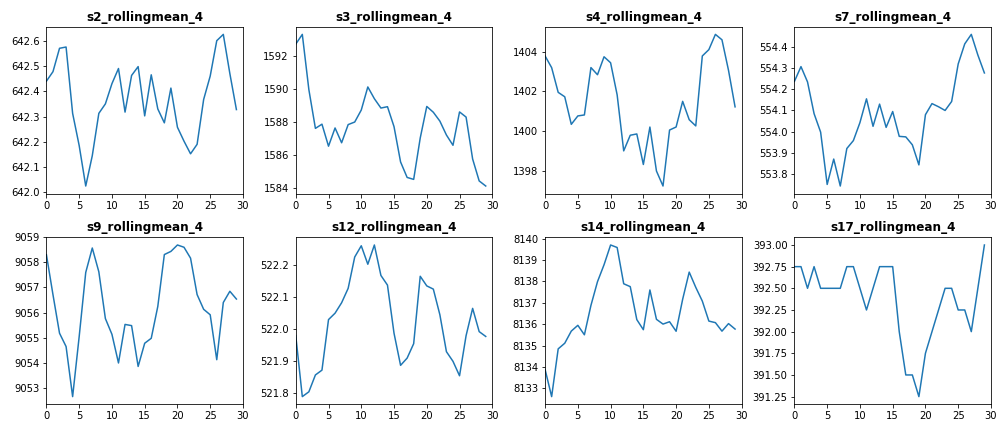 Test Data After Removing Noise (Engine #15)
Test Data After Removing Noise (Engine #15)
3. Normalization
The third step in data preprocessing is features normalization. The goal of normalization is to re-scale each feature to be in [0,1] domain. Feature normalization unifies the scale of all data features, which help ML algorithms to generate accurate models. The following function generates normalized features out of set of numerical data features.
def add_normalized_features(df, features):
'''
This function squashes columns in Spark Dataframe in [0,1] domain.
INPUTS:
@df: Spark Dataframe
@features: list of data features in spark_df
OUTPUTS:
@df: Updated Spark Dataframe
'''
# create Spark window
w = Window.partitionBy("id")
for f in features:
# compute noralized feature
norm_feature = (F.col(f) - F.min(f).over(w)) / (F.max(f).over(w) - F.min(f).over(w))
# add normalized feature to DF
df = df.withColumn(f + '_norm', norm_feature)
return df
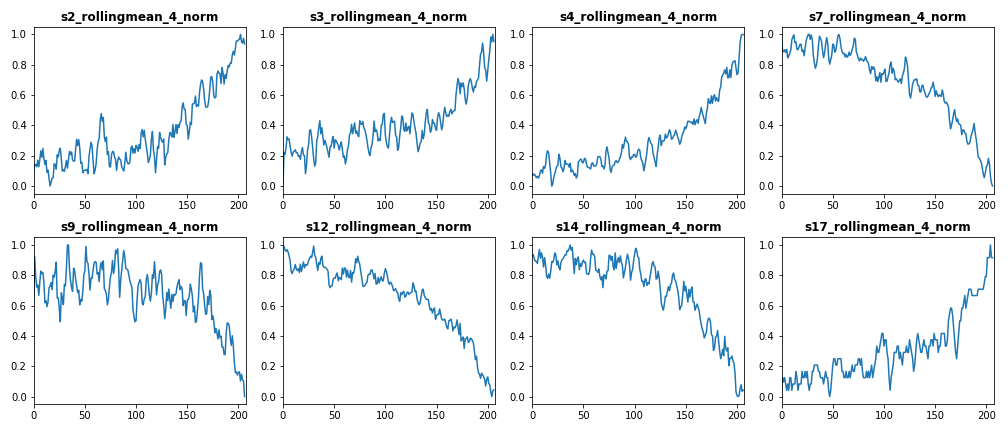
The following figure shows train data features after normalizing them in [0,1] domain. Please note that we normalized the rolling average features (i.e. low-noise data features)
4. Standardization
Another common feature scaling procedure similar to normalization is standardization. In this procedure, we re-scale our features such that each feature has zero mean and unit variance. In predictive modeling we can use normalized features, standardized features, or a collection of both sets to achieve better performance. The following function standardizes a list of numerical features in Spark Dataframe.
def add_standardized_features(df, features):
'''
This function add standard features with 0 mean and unit variance for each data feature in Spark DF
INPUTS:
@df: Spark Dataframe
@features: list of data features in spark_df
OUTPUTS:
@df: Updated Spark Dataframe
'''
# set windows range
w = Window.partitionBy("id")
# loop over features
for f in features:
# compute scaled feature
scaled_feature = (F.col(f) - F.mean(f).over(w)) / (F.stddev(f).over(w))
# add standardized data features to DF
df = df.withColumn(f + '_scaled', scaled_feature)
return df# add standardized features to df
train_df = add_standardized_features(train_df, roll_data_features)
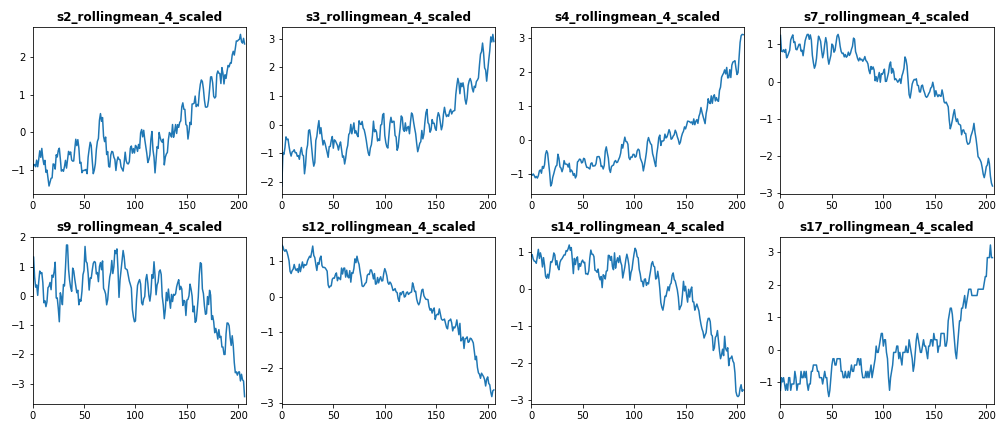
The following figure shows standardized data features generated for train dataset using the above function. Please note that we standardized the rolling average features (i.e. low-noise data features).
Hi there! Such a good short article, thanks!