
1. Idea
[watch video]
Suppose we have a set of observations represented by two variables \(x\) and \(y\). Let’s assume that our observations are group of persons, and the \(2\) variables are persons’ heights (\(x\) axis) and weights (\(y\) axis). If we plot heights and weights in a scatter plot (see below), we can easily find a kind of correlation between them (i.e. as height increase, weight increase as well, and vice versa)
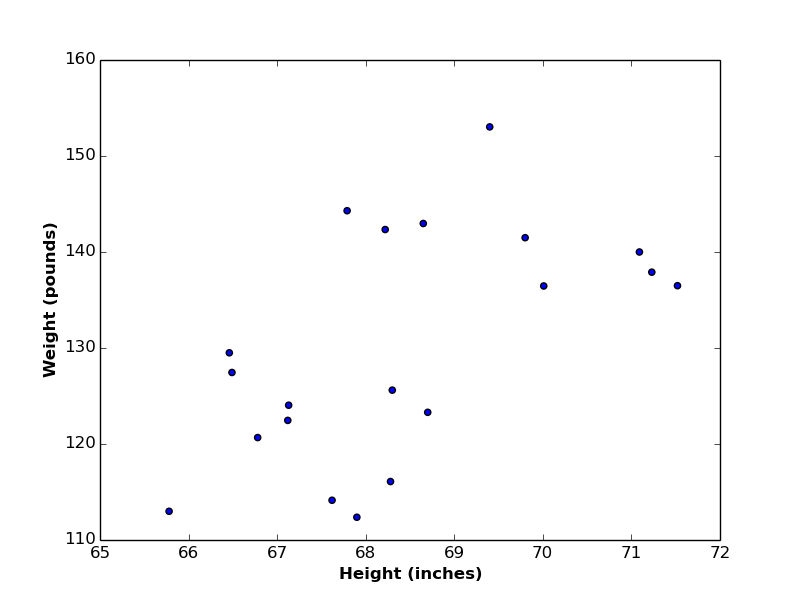
Let’s also assume that we want to find a linear relationship (i.e. linear function) between heights and weights, such that if we have the value of a new person height, we can predict her/his corresponding weight. In this case, we call variable height the independent variable or predictor, and variable weight the dependent variable or target variable.
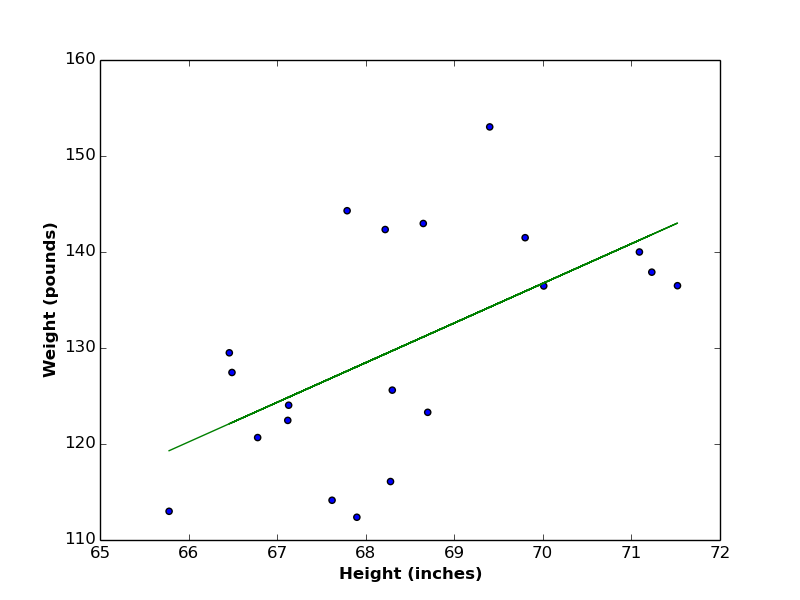
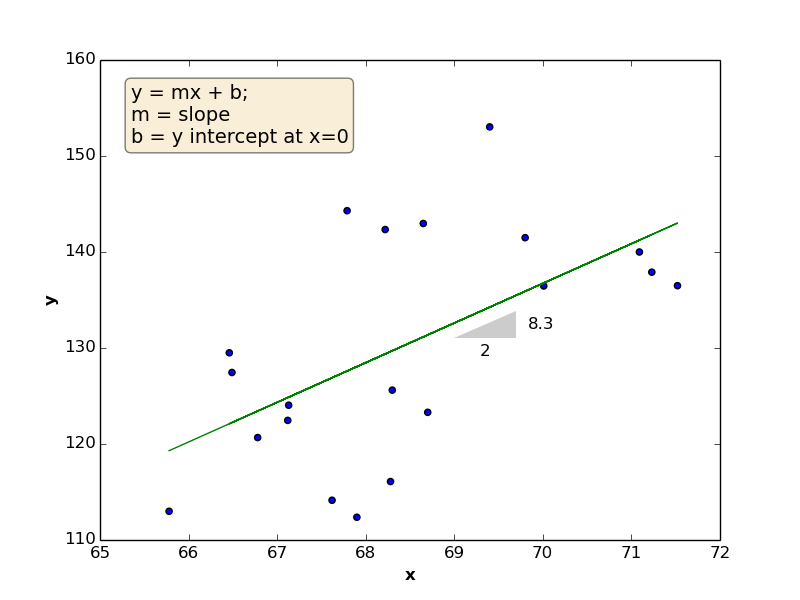
As a reminder, the linear function is defined by \(2\) coefficients (\(m\) is the slope, which reflects the change of \(y\) divided by the change of \(x\)), and \(b\) (the point at which the line intersects with \(y\) axis). In the below figure, \(m = 4.13\) and \(b = -152.43\)
Back to our goal, we need to find a linear function between \(x\) and \(y\), but, which linear function? As you can imagine, there are endless number of lines that can represent such function (see the below figure). So the question would be, which line is the best?
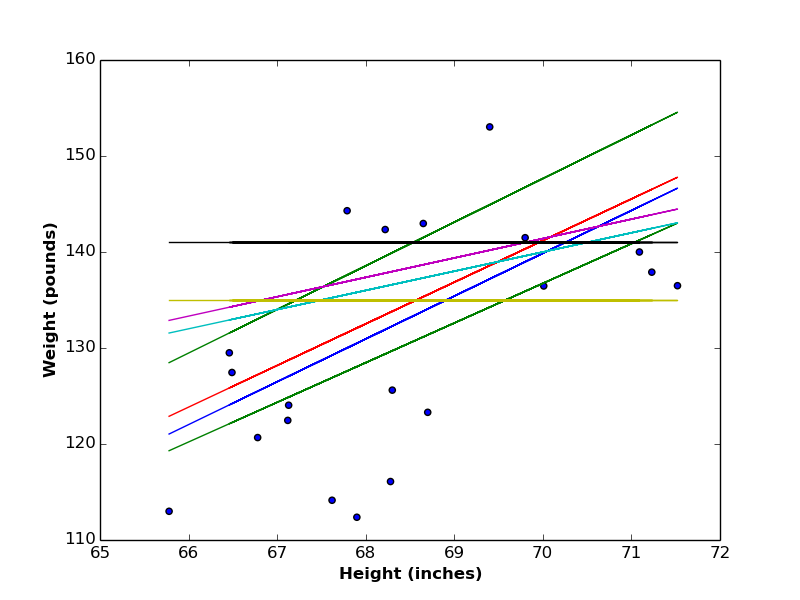
Let’s go to the theory of linear regression, to be able to answer this question.


According to least square approach, and in order to find the best linear function between \(x\) and \(y\), we need to find a vector of coefficients \(\vec{w}\) that minimizes the following function:
\begin{equation} E(\mathbf{w}) = \frac{1}{N}\sum \limits_{i=1}^N [y^{(i)}-f(x^{(i)},\mathbf{w})]^2 \tag{1}\end{equation}
Notations:
- \(x^{(i)}\) and \(y^{(i)}\) are values of variables \(x\) and \(y\) of observation \(i\)
- \(N\) is number of observations
- \(\mathbf{w}\) is vector of coefficients to identify linear regression function
Function (1) is called error function, objective function, or cost function. In this post, a form of error function called Mean-Square-Error (MSE) is used, where squaring differences between true and predicted values allows us to consider positive and negative differences the same, and division by \(N\) allows us to compare different sizes of data using same coefficients’ values.
The function \(f(x^{(i)},\mathbf{w})\) is called linear regression function or hypothesis function, and is defined as:
\begin{equation}
f(x^{(i)},\mathbf{w}) = w_0 + w_1x^{(i)}\tag{2}
\end{equation}
where \(w_1\) is the slope and \(w_0\) is \(y\) intercept at \(x= 0\).
We know from Calculus, that minimizing (or maximizing) a function can be done, by equalizing it’s first derivative to zero, and solving the generated equations to find the corresponded coefficients. As an example, in the below graph, we have a function \(f(x)\) (green). If we want to find the maximum value of \(f(x)\) (Point \(A\)) or the minimum value (Point \(B\)), we compute the function’s derivative \(f'(x)\) (blue), and find the points where \(f'(x)\) intersects with \(x\) axis.
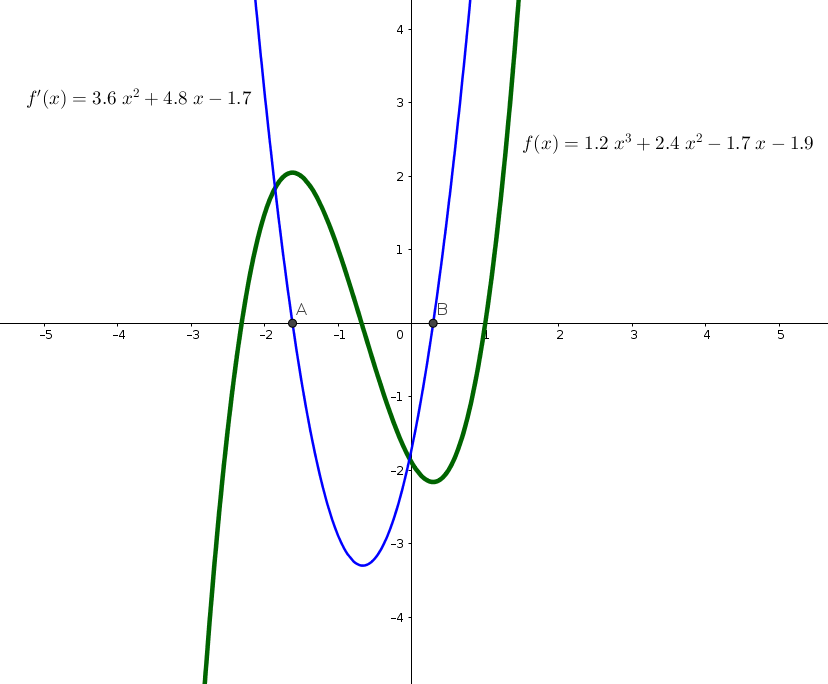
Let’s try to differentiate Equation (1) with respect to \(\mathbf{w}\) and find the values of \(w_0\) and \(w_1\).
compute \(w_0\) (\(y\) intercept at \(x=0\))
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_0}= \frac{1}{N} \sum\limits_{i=1}^N \frac{\partial [y^{(i)} – (w_0 + w_1 x^{(i)})]^2}{\partial w_0}\tag{3}
\end{equation}
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_0}= \frac{1}{N} \sum\limits_{i=1}^N \frac{\partial [{y^{(i)}}^2 -2y^{(i)}(w_0 + w_1 x^{(i)}) + (w_0 + w_1 x^{(i)})^2 ]}{\partial w_0}\tag{4}
\end{equation}
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_0}= \frac{1}{N} \sum\limits_{i=1}^N \frac{\partial [{y^{(i)}}^2 – 2w_0 y^{(i)} – 2 w_1 x^{(i)} y^{(i)} + w_0^2 + 2w_0 w_1 x^{(i)} + w_1^2 {x^{(i)}}^2] }{\partial w_0}\tag{5}
\end{equation}
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_0}= \frac{1}{N} \sum\limits_{i=1}^N -2 y^{(i)} +2 w_0 + 2 w_1 x^{(i)}\tag{6}
\end{equation}
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_0}= \frac{-2}{N} \sum\limits_{i=1}^N y^{(i)} – (w_0 + w_1 x^{(i)}) \tag{7}
\end{equation}
compute \(w_1\) (slope)
for this part, we will differentiate Equation (5) with respect to \(w_1\), as follows:
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_1}= \frac{1}{N} \sum\limits_{i=1}^N \frac{\partial [{y^{(i)}}^2 – 2w_0 y^{(i)} – 2 w_1 x^{(i)} y^{(i)} + w_0^2 + 2w_0 w_1 x^{(i)} + w_1^2 {x^{(i)}}^2] }{\partial w_1}\tag{8}
\end{equation}
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_1}= \frac{1}{N} \sum\limits_{i=1}^N -2 x^{(i)} y^{(i)} +2 w_0 x^{(i)} + 2 w_1 {x^{(i)}}^2\tag{9}
\end{equation}
\begin{equation}
\frac{\partial E(\mathbf{w})}{\partial w_1}= \frac{-2}{N} \sum\limits_{i=1}^N x^{(i)}[y^{(i)} – (w_0 + w_1 x^{(i)})] \tag{10}\end{equation}
Please note, that the only difference between equations (7) and (10), is that when we differentiate the error function with respect to the second coefficient \(w_1\), we multiply the right side inside the sigma by \(x^{(i)}\).
Now, we put both (7) and (10) equations to zero:
\begin{equation}
\frac{-2}{N} \sum\limits_{i=1}^N y^{(i)} – (w_0 + w_1 x^{(i)}) = 0\tag{11}
\end{equation}
\begin{equation}
\frac{-2}{N} \sum\limits_{i=1}^N x^{(i)}[y^{(i)} – (w_0 + w_1 x^{(i)})] = 0\tag{12}
\end{equation}
There are two ways to solve this equations system and obtain \(\mathbf{w}\): a closed form approach, and the gradient descent algorithm.
4. Gradient Descent Algorithm
We can imagine the gradient descent algorithm for linear regression as a \(3\)d graph (see below). We start at random values of \(\mathbf{w}\), compute the corresponded error function \(E(\mathbf{w})\), and iteratively updating \(\mathbf{w}\) in the direction of lowering \(E(\mathbf{w})\), until either \(\nabla E(\mathbf{w})= 0\), or a satisfied converge is reached.
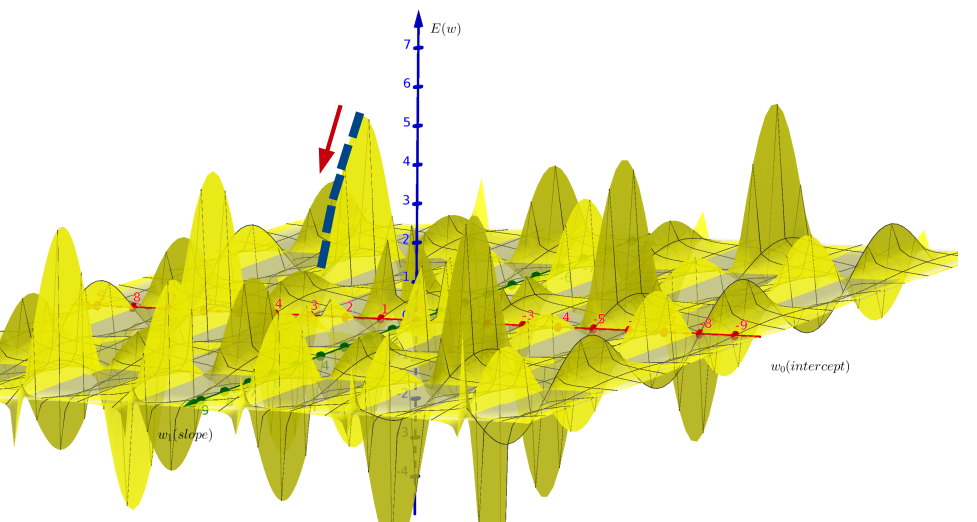
Gradient descent algorithm (listed below) require three input parameters: the cost function \(E(\mathbf{w})\) to be differentiated, initial values of linear coefficients vector \(\mathbf{w}\), and a third parameter called the learning rate. The role of learning rate is to control the algorithm speed while minimizing the error function. On the one hand, if learning rate take high values, the algorithm will converge quickly, but it can fall into a local minima. On the other hand, if learning rate is small, the algorithm may take considerable running time to converge. Different values of \(\eta\) should be tested to select the most probable value for data in hand.
Algorithm1 GradientDescent(\(E(\mathbf{w}),\mathbf{w},\eta\))
- Input:
- \(E(\mathbf{w})\): cost function
- \(\mathbf{w}\): initial values of coefficients vector
- \(\eta\): learning rate
- Output:
- \(\mathbf{w}\): updated values of coefficients vector
- Procedure:
- repeat
- \(w_p=w_p – \eta \frac{\partial E(\mathbf{w})}{\partial w_p}, \forall w_p \in \mathbf{w}\)
- until \(\nabla E(\mathbf{w})= 0\)
- return \(\mathbf{w}\)
Coefficients (\(w_p\)) in the gradient descent algorithm are updated as follows:
\begin{equation}
w_0= w_0 – \eta \frac{-2}{N} \sum\limits_{i=1}^N y^{(i)} – (w_0 + w_1 x^{(i)}) \tag{18}
\end{equation}
\begin{equation}
w_1= w_1 – \eta \frac{-2}{N} \sum\limits_{i=1}^N [y^{(i)} – (w_0 + w_1 x^{(i)})] x^{(i)}\tag{19}
\end{equation}
“Thank you ever so for you article post.Much thanks again. Will read on…”
I hope you find the material useful for you. For more explanation, you are invited to watch the attached YouTube Videos
Hmm it seems like your blog ate my first comment (it was super long) so I guess I’ll just sum
it up what I had written and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog blogger but I’m still new
to the whole thing. Do you have any recommendations for novice blog writers?
I’d certainly appreciate it.
Hi!
I think the first thing you should prepare is the valuable material for your readers. The rest can be easily learned from the Web.
All the best for your Blogging.
Nice post thanks for sharing
Thanks!
You have made some really good points there. I checked on the web for additional information about the issue and found most individuals will go along with your views on this site.
Thanks!