
4. Linear Regression
4.1 Initialize Linear Regression Instance
The first step in regression analysis is to set new instance of LinearRegression() function:
from pyspark.ml.regression import LinearRegression
# init LR instance
lr = LinearRegression(featuresCol = 'features', labelCol = 'label', maxIter=100)
As you notice in the above line, we pass the names we defined in training data vector for independent features (“features“) and target variable (“label“) to LinearRegression() function. We also set the maximum number of iterations of the LR algorithm to 100.
4.2 Optimize Model Parameters
If you want to change the default parametric settings of LinearRegression() function above, you can do so by changing the parametric settings when initializing the object:
# init LR instance
lr = LinearRegression(featuresCol = 'features', labelCol = 'label',
regParam=0.2, elasticNetParam=0.5, maxIter=200)
In the above line, we set the maximum iterations to 200, the regression parameter to 0.2, and the elastic net parameter to 0.5.
4.3 Fit Linear Regression Model to Training Data Vector
The second step is to fit the LR model to our train data vector.
# fit linear regression model
lr_model = lr.fit(train_vector)
Here we build our regression model by passing train data vector to the LR instance created in the previous step.
4.4 Build Test Features Vector
The third step is to build test data vector compatible to the train vector:
# select test features (with same features set as of train vector)
test = test_df.select(test_df["s12_rollingmean_4_norm"],test_df["s7_rollingmean_4_scaled"],
test_df["s12_rollingmean_4_scaled"],test_df["s4_rollingmean_4_norm"],
test_df["s4_rollingmean_4_scaled"],test_df["rul"])
# build test features vector
test_vector = test.rdd.map(lambda x: [x[5], Vectors.dense(x[0:5])]).toDF(['label','features'])
4.5 Get Predictions
After executing the above steps, we can obtain predictions by passing the test vector to the regression model:
# get predictions pred = lr_model.transform(test_vector)
4.6 Evaluate Regression Model
As we have build our regression model and applied it to the test dataset, we can evaluate our regression model. Apache Spark has some nice functions that calculate basic evaluation metrics of regression models. To make use of it, we need to initialize an evaluation object:
from pyspark.ml.evaluation import RegressionEvaluator
# initialize regression evaluation instance
evaluator = RegressionEvaluator(predictionCol='prediction', labelCol='label')
Now we can use this evaluation instance to calculate some nice evaluation metrics. The following lines of code prints R Squared, Mean Square Error (MSE), Root Mean Square Error (RMSE), and Mean Absolute Error (MAE).
# print evaluation metrics
print "R-squared= ", evaluator.setMetricName('r2').evaluate(pred)
print "MSE= ", evaluator.setMetricName('mse').evaluate(pred)
print "RMSE= ", evaluator.setMetricName('rmse').evaluate(pred)
print "MAE= ", evaluator.setMetricName('mae').evaluate(pred),
4.7 Visualize Evaluations
By applying the above steps to a subset of Engines (Engines 18, 30, 38, 12, 34), we obtained evaluation results as plotted below.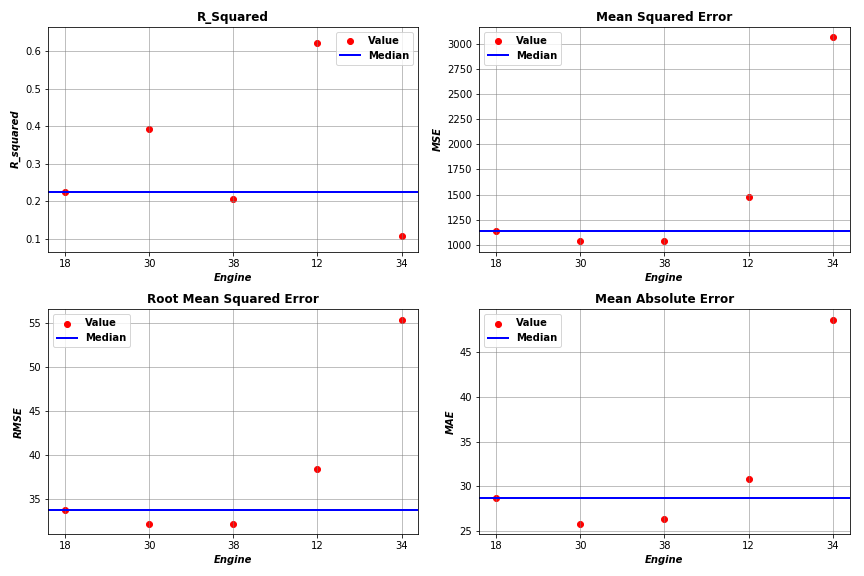
5. Generalized Linear Regression
5.1 Initialize Generalized Linear Regression Instance
By following the same steps above, we can build another regression model called Generalized Linear Regression using the below code:
from pyspark.ml.regression import GeneralizedLinearRegression
# init GLR instance
glr = GeneralizedLinearRegression(featuresCol = 'features', labelCol = 'label', family="gaussian",
link="identity", maxIter=50, regParam=l)
Where regression parameter \(l\) can take one of the values [0, 0.5, 1, 10, 30, 50].
5.2 Visualize Evaluations
By evaluating the above model using different input parameters’ settings, we can compare the model performance using each setting and select the most accurate one.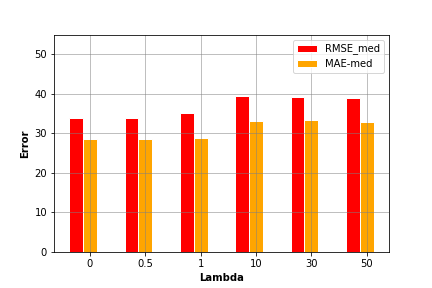 In the above plot, we find that setting regression parameter to 0 generates the lowest error values.
In the above plot, we find that setting regression parameter to 0 generates the lowest error values.