
1. Problemstellung
Medizinischen Geräten wird erwartet, dass sie äußerst genau und (hoffentlich) fehlerfrei funktionieren, da ein unkontrolliertes Fehler das Leben von Patienten gefährden kann. Motiviert von diesem Geschäftsziel möchte ein Österreichischer Hersteller von medizinischer Geräte das Verhalten seiner täglich verwendeten Geräte verstehen, indem er den Stromverbrauch jedes Geräts und seinen Einfluss auf die Fehler dieses Geräts untersucht. Ziel dieser Fallstudie ist es, ein Machine Learning (ML) -Modell zu entwickeln, das das Verhalten von Medizingeräte versteht und zukünftige Fehler vorhersagen kann, bevor sie auftreten. Dieses ML-Modell soll dem Hersteller helfen, eine zuverlässige Strategie für die Wartung seiner Geräte zu entwickeln. Diese Wartungsstrategie sollte – so weit wie möglich – mögliche Fehler (nach dem Verkauf) vermeiden und die Anzahl unnötiger Wartungsbesuche bei seinen Kunden minimieren.
2. Primärdaten
2.1 Gerät Ereignissen
Sensordaten von medizinischen Geräten bestehen aus einer Liste von Ereignissen für jedes Gerät. Jedes Ereignis hat einen Zeitstempel und ein Ergebnis. Ereignisergebnisse können “ok“, “warning” oder “failure” sein. Wenn das Ereignis “ok” lautet, bedeutet dies, dass das Gerät erfolgreich ausgeführt wurde. Wenn während des Ereignisses ein Fehler auftritt, wird das Ergebnis “failure“. Darüber hinaus generieren einige Ereignisse “warning” Ergebnisse. Diese Warnungsereignisse werden durch das Motorsteuersystem in jedem Gerät aufgrund eines erhöhten Energieverbrauchs erzeugt und führen nicht notwendigerweise zu einem Fehler.
Zusätzlich zu den Ereignisergebnissen wird jedes Ereignis als “Betriebs” oder Test resultat klassifiziert. Sensormessungen von “Test” Ereignissen werden direkt nach der Wartung durchgeführt, wenn die Geräte typischerweise gut arbeiten. Alle anderen Sensormessungen sind als Betriebsereignisse gekennzeichnet.
2.2 Gerät Lebenszyklus
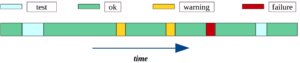
Während seines Lebenszyklus erzeugt jedes Gerät nach jedem Ereignis eines von vier möglichen Ergebnissen (siehe Abbildung unten). Wenn das Ereignis erfolgreich ausgeführt wird, wird “ok” Ergebnis generiert (grüne Bereiche). Nach der planmäßigen Wartung werden “test” Ereignisse direkt danach ausgeführt. Die entsprechenden Sensormessungen der Testereignisse spiegeln die bestmögliche Leistung des Geräts wider, und werden als “test” Ereignisse (hellgrüne Bereiche) bezeichnet. Gelegentlich erzeugen Geräte “warning” Ergebnisse, aufgrund erhöhter Stromverbrauch (gelbe Bereiche). Wenn ein Ereignis nicht ordnungsgemäß ausgeführt wurde, erzeugt das Gerät das Ergebnis “failure” (roter Bereich).
2.3 Datenkonsistenz
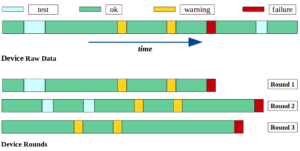
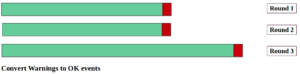
Bevor wir die Daten modellieren, müssen wir die nützlichsten Teile davon für die Vorhersageaufgabe extrahieren. Zuerst gruppieren wir Ereignisse in diskrete Runden auf. Jede Runde enthält Ereignisse bis zu einem Fehler. Das folgende Diagramm erläutert diesen Schritt.
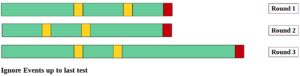
Zweitens, und für jede Runde ignorieren wir Ereignisse bis zum letzten Test vor dem Fehler (siehe folgendes Diagramm). Der Grund dafür ist, dass wir nicht wissen, wie stark das Gerät bei der Wartung beschädigt wurde. Dementsprechend sind diese Ereignisse schwer objektiv zu klassifizieren.
Schließlich, und weil wir keine Beziehung zwischen “warning” und “failure” Ereignissen haben, betrachten wir “warning” Meldungen als “ok” (folgendes Diagramm). Darüber hinaus wäre das Zielmodell vorhersagende Fehlerereignisse, unabhängig davon, ob Warnungen vor Fehlern vorhanden waren oder nicht.
2.4 Ereignisverteilung
Diese Studie wurde an drei Medizingeräte (A, B und C) durchgeführt, von denen jedes unter verschiedenen technischen und betrieblichen Bedingungen abläuft. Jedes Gerät hat eine unterschiedliche Anzahl von Ereignissen pro Tag. Die Ereignishäufigkeit liegt zwischen 0 und mehreren hundert Ereignissen pro Tag. Die folgende Abbildung zeigt die Verteilung der Ereignisse pro Tag für jedes Gerät in der Studie.

Als Daten fehlende Werte enthalten, verwenden wir die durchschnittliche Häufigkeit der Ereignisse pro Tag, um die tägliche Aktivität jedes Geräts anzuzeigen. Wie die obige Abbildung zeigt, hat jedes Gerät eine ganz andere Frequenz (Gerät A hat fast 8 Ereignisse/Tag, B hat 89, und C hat 11 Ereignisse/Tag).
2.5 Datenbeschriftung
Nach dem Anwenden der obigen Schritte auf Primärdaten, wird jede Runde in drei Zeitzonen klassifiziert, basierend auf dem Verschlechterungsgrad des Geräts. Diese Zonen sind wie folgt definiert:
- Normal Zone: Diese Zeitzone findet typischerweise zu Beginn jeder Runde statt. Während dieser Zeit arbeiten die Geräte gut und es ist nicht nötig, sie für die Wartung zu planen.
- Warning Zone: Diese Zeitzone steht zwischen den Zonen Normal und Alarm jeder Runde. In diesem Zeitraum beginnt sich die Geräteleistung zu verschlechtern, und es ist an der Zeit, das Gerät in den Wartungsplan aufzunehmen.
- Alarm Zone: Diese Zeitzone kommt direkt vor den Fehlerereignissen. Innerhalb dieses Zeitraums wird erwartet, dass sich die Geräteleistung dramatisch verschlechtert und dass ein schneller Wartungsbesuch durchgeführt werden muss, bevor das Gerät ausfällt.

In dieser Studie, und wie mit dem Hersteller vereinbart, wählten wir Warning- und Alarmzonen zu jeweils 7 Tagen aus, die bis zu zwei Wochen vor dem Auftreten eines Fehlers summierten.
3. Daten Vorverarbeitung
3.1 Erstellung den Datenfunktionen
Jedes Gerät verfügt über mehrere Sensoren, und während jedes Ereignisses werden die entsprechenden Messungen jedes Sensors aufgezeichnet. Bei jedem Ereignis verbrauchen Sensoren unterschiedliche Mengen an elektrischer Energie. Diese Mengen an elektrischer Energie werden als eine Folge von Zahlen aufgezeichnet. Die Länge der Messsequenz für ein bestimmtes Ereignis gibt die Zeit an, die das Gerät benötigt, um dieses Ereignis zu beenden. Mit anderen Worten, je länger die Sequenz ist, desto länger dauert das Gerät, um das Ereignis zu beenden. Da jedes Gerät über eine unterschiedliche Anzahl von Sensoren verfügt und jeder Sensor bei jedem Ereignis unterschiedliche Sequenzlängen aufweist, berechnen wir die folgenden Variablen aus den Messungen der Sensoren:
- count: Länge der Messsequenz (auch als Signal der Ereignisdauer)
- sum: Summe des Messvektors (auch als Signal für die Gesamtmenge an Strom, die von jedem Sensor während des Ereignisses verbraucht wird)
- avg: Mittelwert des Messvektors.
- var: Varianz des Messvektors.
- min: Minimalwert im Messvektor.
- max: Maximalwert im Messvektor.
- first: erster Wert im Messvektor.
- last: letzter Wert im Vektor der Messungen.
3.2 Entfernung von Dimensionen mit geringer Varianz
Nach dem Erstellen der oben genannten statistischen Dimensionen reduzieren wir den Feature-Speicherplatz durch das Entfernen von Dimensionen mit geringer Varianz aus Daten. In dieser Studie wird jede Dimension mit einer Abweichung kleiner oder gleich 0.5 aus den Daten entfernt.
3.3 Skalierung den Dimensionen
Um die Dimensionen zu standardisieren, wenden wir ein Standardisierungsverfahren mit Null-Mittelwert und Einheits-Varianz auf die Menge von Dimensionen an, die nach dem Entfernen von Varianten mit geringer Varianz verbleiben.
3.4 Dimensionsreduktion
Ein gemeinsamer Vorverarbeitungsschritt vor der Datenmodellierung besteht darin, den Datenraum zu reduzieren. Dieser Schritt hilft Klassifikatoren beim schnellen Erstellen von Modellen (speziell für solche, die auf paarweisen Abstandsmatrizen basieren) und erleichtert die Datenvisualisierung. In dieser Studie wählen wir Principal Component Analysis (PCA), um unseren Feature-Raum zu reduzieren. PCA ist eine weit verbreitete Technik zur Dimensionsreduktion. PCA erstellt eine neue Gruppe von Features aus den ursprünglichen Daten, die die in den ursprünglichen Features enthaltene Varianz besser beschreibt. Die folgende Abbildung zeigt die Varianz der ersten 10 Hauptkomponenten (PCs) von Gerät B (links) sowie ein Streudiagramm von Datenbereichen, die von den ersten beiden PCs gezeichnet wurden (rechts).
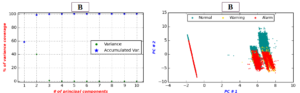
Wie die Abbildung zeigt, erfasst PCA fast 100% der Datenvarianz innerhalb der ersten beiden PCs. Der Einfluss kann im rechten Streudiagramm dargestellt werden, wo verschiedene Bereiche mehr getrennt werden. Die Zone “Normal” scheint in der oberen Hälfte des Diagramms konzentriert zu sein, während sich die Zonen “Warnung” und “Alarm” normalerweise im unteren rechten Bereich des Diagramms befinden. Darüber hinaus wird ein Cluster von “Alarm” Ereignissen als eine Linie links neben dem Streudiagramm neben einem kleinen Cluster von “Normal” Ereignissen getrennt.
In Teil 2 dieser Studie diskutieren wir Daten Modellierungs und Auswertungsmetriken für diesen Anwendungsfall der vorausschauenden Wartung.