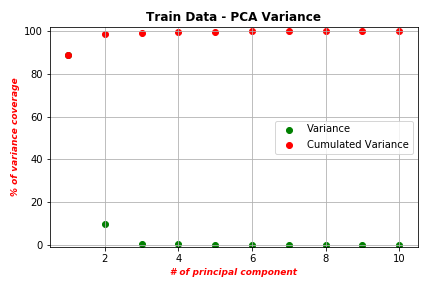
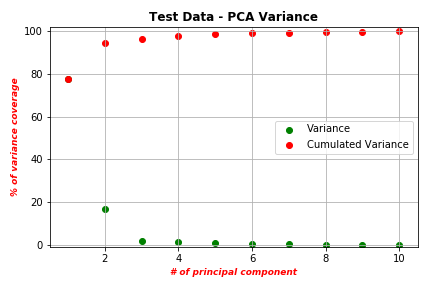
As we see in the above figures, the PCA algorithm managed to compress almost all data variance in the first 4 PC features. This means we managed to efficiently reduce our data dimensionality from 24 features to 4 features without losing variance. Now, let’s visualize our PC features.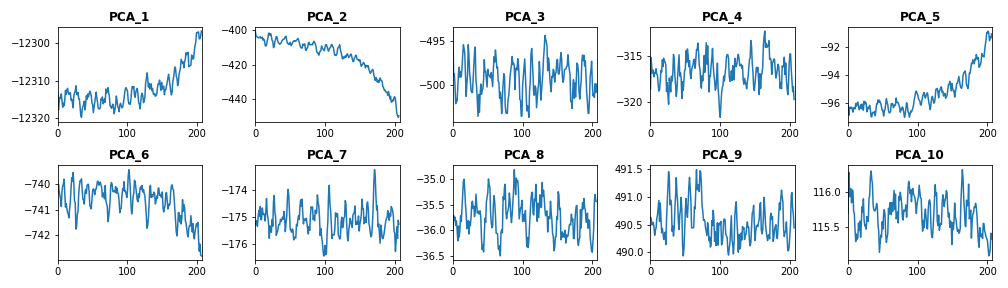 As the figure shows, the generated PCs have different scales. Therefore, we need to scale those features using normalization and standardization procedures.
As the figure shows, the generated PCs have different scales. Therefore, we need to scale those features using normalization and standardization procedures.
3. Standardize PC Features
As with PC normalization, we also generate standardized PC features without partitioning our data per engines. The following function does the job for us.
def add_standardized_features_unpartitioned(df, features):
'''
this function add standard features with 0 mean and unit variance for each data feature in Spark DF
INPUTS:
@df: Spark Dataframe
@features: list of data features in @df to be standerdized
OUTPUTS:
@df: updated Spark Dataframe
'''
for f in features:
# compute min, max values for each data feature
cur_mean = float(df.describe(f).filter("summary = 'mean'").select(f).collect()[0].asDict()[f])
cur_std = float(df.describe(f).filter("summary = 'stddev'").select(f).collect()[0].asDict()[f])
print f, ' cur_mean: ', cur_mean, ' cur_std: ', cur_std
# create UDF instance step 1 (subtract mean from feature)
standardize_Udf = F.udf(lambda value: (value - cur_mean) / cur_std, DoubleType())
# add standardized data features
df = df.withColumn(f + '_scaled', standardize_Udf(df[f]))
return df
# add standardized features to train DF
train_df = add_standardized_features_unpartitioned(train_df, pca_features)
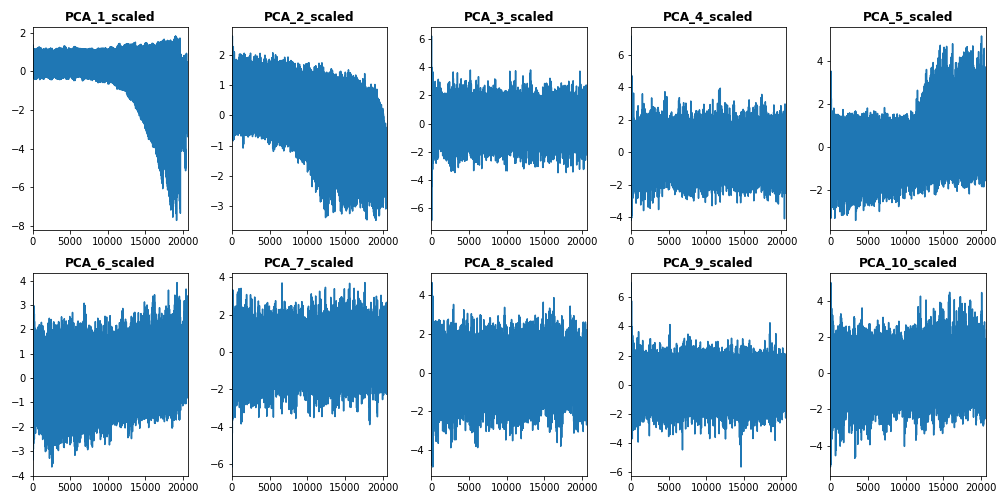
The following figure shows standardized PC features of all engines.